
这周三雷军在微博上分享了一张用户和小爱同学最喜欢聊的内容。从图中看来,让小爱同学来控制家电、打电话、获取信息等是用户最喜欢说的话题。
而像“雷军有多少钱”这类的比较撩的话题,小爱同学也能完全hold得住:“我爸爸有多少钱管你什么事,哼”。集机智与傲娇于一身,可以说是很能取悦用户了。

但另一面也有“为什么小爱能打开电视,却关不了电视”等的吐槽…..虽然以智能音箱为代表的语音交互类产品已经成功打开了市场,但实际上,遇到的问题比得到的趣味要多得多。
带有方言口音的用户,得到的很可能是“我不明白你在说什么”的答复;语音助手也分清“去某地”和“去土豆皮”的区别;家里的智能电视、音箱,还是会出现莫名其妙被唤醒,开始唱歌……
完善用户体验成为智能语音产品市场化最大的难点和痛点。详细来说,完整的语音交互体验需要在“听清”、“听懂”两个环节做到极致,才能让智能语音“神形具备”,进而满足用户需求。
给机器几只耳朵合适? 大自然已经给出了答案
“听清”离不开语音识别技术的支撑,来给机器能够听清物理世界的“耳朵”。其中又分为“前端”和“后端”两部分,“前端”通过麦克风对语音进行识取、检测、降噪、特征提取等。
“后端”通过已有的 “声学模型”和“语言模型”,对识取到的语音信号进行识别(又称“解码”),得到语音背后的文字信息。另外,后端还可以通过“反馈模块”对用户的语音进行自学习,不断优化原有的“声学模型”和“语音模型”,进一步提高识别的准确率。
一般来说,要想“听清”,只要前端麦克风数量越多,对空间划分越仔细,那么相应语音增强和降噪效果会更好。
但实际上还要考虑到成本问题,就拿智能语音音箱来说,双麦克风阵列的 Google Home 售价129美元,采用的是6+1环形麦克风阵列 Amazon Echo售价为179.99美元,足足差了50美元。

虽然现在市场上的智能语音类产品使用单麦/双麦和多麦克风列阵的都有,科大讯飞产品经理林学仕还是认为自然界已经给了我们答案:人只有两只耳朵。
“单麦没有办法排成列阵,多麦克风阵列能够实现的能力,随着算法的升级和技术迭代,也能在双麦上实现。因此林学仕认为低功耗、低成本、体积小巧的双麦,能够带来更大的场景探索的边界,还是会成为主流。” 林学仕在3W举行的OpenForum活动中说道。
另外,在进场交互领域,还有一项前沿技术——光学麦克风,比如人在讲话的时候,脸部的肌肉会有变化,光学麦克风能够将振动信号从背景通背景噪音中隔离出来,并转变为用于传输的语音信号,大大现实降噪的效果。
走出十字路口 还是整个行业的难点
让机器能够“听清”之后,就是要“听懂”了。这需要机器的“AI大脑”进行语义理解,转化为文本的语音,再通过机器学习和自动化搜索等,进行语义分析,来理解用户的意图。
“听清”如同对一本单词表的比对过程,“听懂”却变成了一本百科词典、甚至是维基百科的理解过程。这也是最矛盾和最难的地方。机器基于深度学习、搜索等技术可以把具体的词语含义和图片、句子等进行联系,找到强关联的答案。
但机器不能理解抽象的概念,也没有认知关联。比如对于喜欢、飘渺等类的词语,机器是无法理解的。这也是目前人工智能、语音交互等始终处于被动式控制状态的原因。机器只能在特定场景下实现相对简单、命令清晰的自动化操作。

一旦下围棋的阿尔法狗或着谷歌“猜画小歌”被用到其他的场景中,还是需要时间去适应和调试。如同在十字路口进行交通管制的警察,通过特定清晰的执行命令来工作,但是走出这个十字路口,面对更加多变和复杂的社会环境,也会变得无能为力。
现在语义理解通常有三层意思,一种是指令型的理解,比如在家居环境中,对智能家居进行控制;第二种是问答系统,通过对产品说明书和问答模版进行阅读理解,可以对用户的提问,进行词句分析,然后给出相应的答案;第三种是能够主动互动聊天的,目前来说还是一大行业难点。
降低语音技术的门槛 扩展产品的深度能力
所以在特定的场景中,主要还是靠工程师手动敲代码,来实现特定的语音指令,添加语音识别的具体指令的含义,并与实际的动作联系到一起。
小爱音箱能够“机智”地回答用户撩拨类的问题,可能话术还是出自网友的脑洞,然后被工程师写进了“脚本”。
“这样的做法有着技术门槛高、开发成本高、维护难度高的问题,在应用扩展深度和效率上都会受到限制。” Naturali 创始人兼CEO邬霄云认为,构建智能语音生态的较量,除了准确率,还要注重语音技能的拓展能力。
对于大厂商来说,一般只关注头部场景的需求,也就是头部的语音交互过程,比如能够满足语音交互控制家电、导航、搜索等特定场景需求,但在产品的深度上仍然难以有更细致的开发。
比如通常语音助手能够打开微信等App 软件,但是并不能进一步完成给某人发信息、发红包的动作。 那么既然机器最终满足的是用户需求的需求,为什么不可以让用户自己定义需求具体的动作和深度呢?
Naturali提出了一个可实行的办法,发布了“语音交互界面VGUI”(声音图形用户界面)的概念,也就是以声音控制图形界面的操作。
VGUI助手可以将用户的意图通过语音对话与APP的操作关联起来,将语音指令转化为一系列点击、滑动等操作,用户能够跳转到最终想去的页面。另外,Naturali把语音技能平台不仅开放给开发者,产品经理、运营人员也能上手操作。
通过 “布点语音”语音助手APP在手机上进行技能录制后,就可以在网页端登陆到平台下的技能工场中进行技能管理,轻松完成从创建、编辑、到语音技能发布的整个流程。
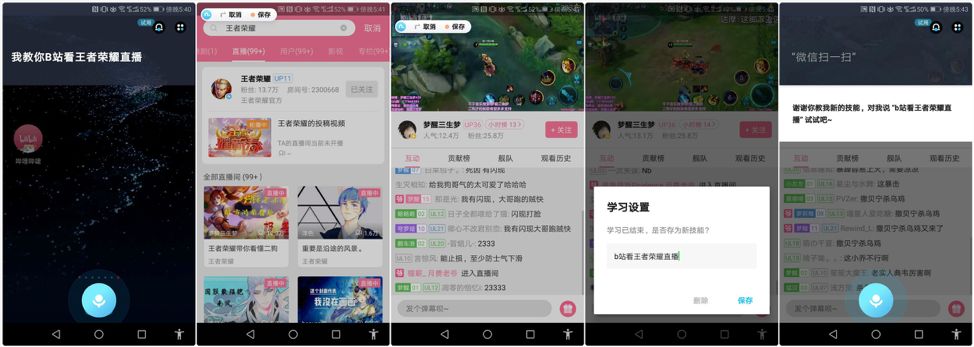
用布点语音教会手机看王者荣耀的新技能
这将语音交互类产品的技术门槛和开发难度就大大降低,比如通过手机语音助手就能直接实现“给微信上的某某发多少钱红包”的操作,扩展了语音助手在移动设备上的服务深度,来完善用户体验和功能。
总的来说,智能语音已经在移动设备、汽车、家居、客服、教育、医疗等行业,形成了基于自然语言处理(NLP)和语义理解技术的产品和服务,提供信息获取、控制设备、用户分析等功能。
但是语音交互体验离真正的人工智能还有很大的差距。在“听清”、“听懂”这两大环节,都离不开机器学习的自动优化,和人为的主动干预。而更好的用户体验解决方案一定会在技术创新和场景应用创新的驱动下,有更多的优化和完善。
点赞(0)
你可能喜欢



说点什么
全部评论
